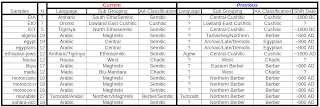
A subset of the Intra-African dataset I have includes Afrasans, or Afroasiatic speakers. Afroasiatic is typically divided into 6 major categories or groups; Semitic, Berber, Egyptian, Chadic, Cushitic and Omotic. A 7th, but nearly extinct group, known as Ongota is contentious, but is by some included as its own branch within the Afroasiatic phylum. All of these Language groups, with the exception of Semitic, are exclusively found in Africa. The 211 Afrasan samples in the dataset belong to 4 or 5 of those groups mentioned, depending on how one accounts for any language shifts (that is shifts within the wider Afrasan phylum) that might have occurred. A rough table is shown below associating the 211 samples with current, and in some cases previously spoken language or language groups of Afroasiatic.
In general, Afroasiatic is thought to have emerged somewhere in the North Eastern section of Africa, anywhere from Ethiopia to Southern Egypt, in the genetic (Autosomal) sense, this area can perhaps be viewed as where such populations inhabiting that area in Africa, lie along a diagonal axis of the C1 vs C3 Intra- African MDSplot (at ~34°
from the horizontal), as highlighted below: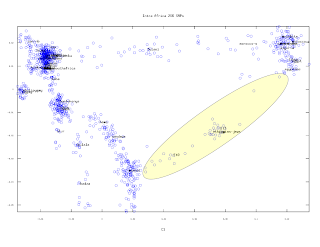
MDS plots
After extracting the 211 AA speaking samples from the 1065 sample African Dataset, I performed an MDS Analysis on it as seen below.
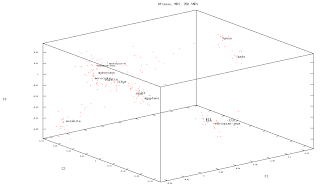
Component 1 separates Berber/Semitic/Egyptian speakers from Chadic speakers, with Ethiopian Semitic/Cushitic speakers plotting somewhere in between, but closer to the former in this separation. Component 2, separates Ethiopians+Egyptians from the rest.
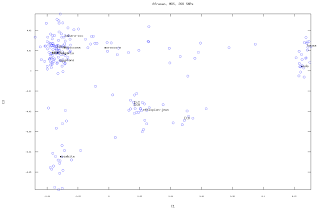
Component 3 Separates the Mozabites from the Rest, with Ethiopians again retaining an intermediate position.
Model Based Analysis
The Logical value for a K selection would be 6, i.e. equivalent to the number of known Afroasiatic subgroups, however, since Omotic speakers are not present in the Dataset, I went ahead and run a K=5 unsupervised ADMIXTURE Analysis for the Afrasan Dataset.
The K=5 ADMIXTURE run produced the following FST distances,

The biggest separation for both Axis is for the cluster I nicknamed Cushitic, while the Berber, Semitic and Mozabite clusters appear pretty close, with the Mozabites looking a bit isolated.
The Median proportions for the clusters can be seen below.

The fact that the mozbites formed their own cluster, is intriguing, although one would suspect that inbreeding may play a role, since it can also be seen how the Mozabites cluster away from other North Africans in the 3D MDS plot, almost forming their own group.
Therefore, to see what this analysis would look like without the Mozabites, I took all 27 of them out, leaving me with 184 AA speaking samples.
I repeated the same analysis as above on the newer Dataset.
MDS Plots



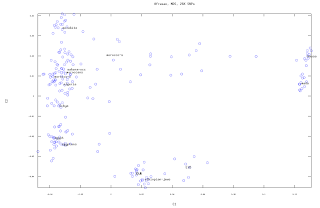
Components 1 and 2 behaved the same way as when the Mozabites were included, Component 3 however, without the Mozabites, separates Berber and Cushitic speakers from the rest to almost the same degree, unlike when the Mozabites were included.
Model Based Analysis

This second iteration of the Afrasan dataset that did not include the Mozabites created a Cushitic, Chadic, Berber and Egyptian clusters, with a 5thcluster which looked like a relic that is present in trace amounts in all the Afrasan samples except the Mada and Hausa. The Egyptian cluster is also found in highland Ethiopians, it also shows a more frequent occurrence of high Standard Deviation relative to all the other clusters;

So the Egyptian cluster looks like it gives less of a linguistic signal than the other clusters, it could potentially be inclusive of a Semitic signal as well as maybe other types of non-Afroasiatic Eurasian affinities.
It would be of great interest to see where Omotic speakears would fit into this analysis.
