This is about an observation made when I introduced the Yemenis (from Behar (2010)) into an ADMIXTURE analysis of the Afrasan Dataset (x Mozabites).
At K=5 the dataset behaves as expected, i.e similar to the K=5 analysis without the Yemenis, they show a high amount of the 'Egyptian' cluster, on par with the Egyptians on median, the remaining cluster distributions were also similar to the K=5 analysis without the Yemenis.

However, the strange thing happens when you reduce the number of assumed discrete populations by 1 to K=4, a difference occurs in the results between when the Yemenis are included and when they are not.
![]()
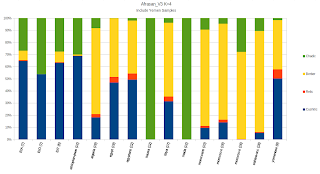

Above, when you run the dataset @ K=4 and include the Yemenis, the Cushitic cluster now peaks in the Ethiopian-Jews instead of the EtO samples, the Egyptians and Yemenis also seem to posses a multi-clustered composition, in almost equal proportions of both the Berber and Cushitic clusters, with the previous Egyptian/semitic cluster reduced to a 'relic' cluster. Another observation is that the remainder of the clusters in the Ethiopian samples are all, for the most part, affiliated with the Chadic clusters, however the Cushitic cluster is closest to the Berber cluster on an Fst basis.
Next, when you look at a K=4 run and the Yemenis are not included, it is back to the previous observation in a peak of the Cushitic cluster in the EtO samples, along with the Egyptian cluster being dominant in the Egyptians.


In order to check, either with my result compiling codes, sample correlation files, or something else was not wrong with the ADMIXTURE run, I re-run the Afrasan Yemeni inclusive dataset again @ K=4, only to get the same results. So I do not think this is an error, something happens with the cluster distributions at K=4 when the Yemenis are included but disappears back to 'normal' at K=5, this means that K=2 and K=3 need to be run for both datasets to get an insight into where this difference in results during the introduction of Yemenis is arising from.
Update: Taking a look at the K2 and K3 ADMIXTURE analysis for the two datasets, one which includes the Yemenis and the other that doesn't respectively.
![]()
![]() For the Dataset that includes the Yemenis (above), @ K=2, the Chadic speakers are separated from the rest, Ethiopians occupying an intermidiate position but leaning more towards the latter group. @ K=3 a Cluster emerges that peaks in the Ethiopian Jews but is also heavily present in both the Egyptians and the Yemenis.
For the Dataset that includes the Yemenis (above), @ K=2, the Chadic speakers are separated from the rest, Ethiopians occupying an intermidiate position but leaning more towards the latter group. @ K=3 a Cluster emerges that peaks in the Ethiopian Jews but is also heavily present in both the Egyptians and the Yemenis.
Update: Taking a look at the K2 and K3 ADMIXTURE analysis for the two datasets, one which includes the Yemenis and the other that doesn't respectively.


For the Dataset that does not include the Yemenis (below), @ both K=2 and K=3 a very similar breakdown of the clusters as above is observed.


Cluster Progression Summary.
V2= w/o Yemenis,


